Chen X, Li L J, Fei-Fei L, et al. Iterative visual reasoning beyond convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7239-7248.
1. Overview
1.1. Motivation
- current recognition systems lack the capability to reason beyond stack of Conv with large receptive fields
- reasoning via top-down modules (UNet) or explicit memories
- local pixel-level reasoning lacks a global reasoning power
- assume enough examples of relationships in training data but not. (relationships grow exponentially and most reasoning requires learning from few or no example)
- a good image understanding is usually a compromise between background knowledge learned a prior and image-specific observations
In this paper, it proposed a novel framework for iterative visual reasoning (incorporate both spatial and semantic reasoning)
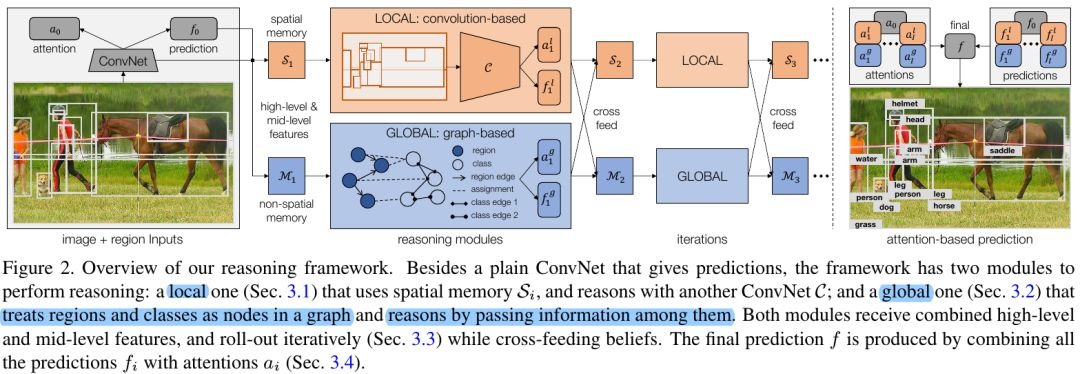
- local module. use parallel updated spatial memory (pixel-level reasoning)
- global graph-reasoning module
- knowledge graph. node→class; edge→ different types of semantic relationships
- region graph. node→region; edge→spatial relationships
- assignment graph. assign regions to classes
- roll-out iteratively and cross-feed predictions
- combine the prediction with attention mechanism
- Dataset. ADE, Visual Genome (VG) and COCO
1.2. Related Works
- Visual Knowledge Base. accumulate structured knowledge automatically from the web
- Context Modeling
- Relational Reasoning.
- symbolic approaches
- apply neural networks to the graph structured data
- regularize the output of networks with relationships
2. Methods
2.1. Local Module
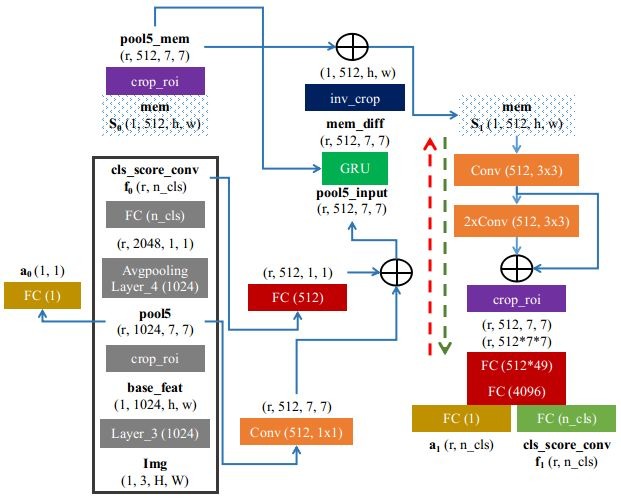
- S. 1 x 512 x h x w
- f. logits before sotfmax
- input feature. mid-level feature (Layer_3) + high-level feature (f)
- (s_r) feature of each region is crop and resize to 7x7
memory of GRU
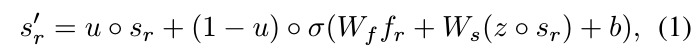
parallel update. a matrix to keep track of how much a region has to a memory cell
- memory S contains two-dimensional image structure and the location information
2.2. Global Graph Reasoning Module

- spatial path + semantic path
- input feature. mid-level feature (Layer_4, after avg) + high-level feature (f)
2.2.1. Region-Region
- relationship of edge. left/right and top/bottom (pixel-level distance and normalize to [0,1])
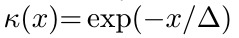
△=50 bandwidth
- closer regions are more correlated
2.2.2. Region-Class
- propagate beliefs from region to class
- backward from class to region
- rather than only linking to the most confident class, it chooses full softmax score p
2.2.3. Class-Class
- commonsense knowledge. is-kind-of, is-part-of
other relationships. actions, prepositions
The end-goal is to recognize regions better, all the class nodes should only be used as intermediate “hops” for better region representations.
- Use three stacks of below operations with residual connections
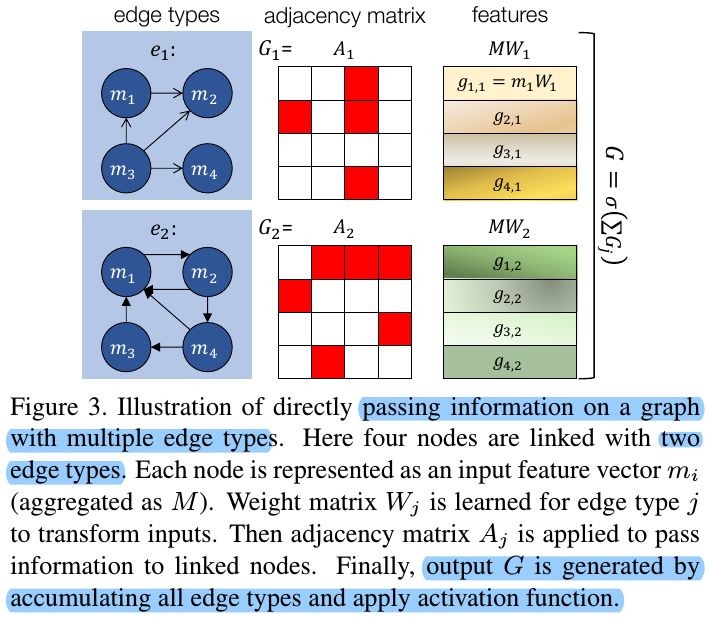
2.2.4. Spatial Path

- M_r (R, D). nodes of region
- A_e (R, R). adjacency matrix of edge type e
- W_e. weight
2.2.5. Semantic Path

- map regions to classes
- combine intermediate features AM_rW with class features M_c
- aggregate features from multiple types of edges between classes
2.2.6. Merge
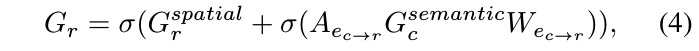
- first to propagates semantic information back to regions
2.3. Iterative Reasoning & Cross-feed
- both the local and global features are concated together to update the memories S_{i+1} and M_{i+1} using GRU
2.4. Attention
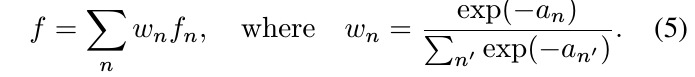
- N = 2I + 1; I is iteration times
2.5. Loss Function
- plain ConvNet loss L_0
- local module loss L^l
- global module loss L^g
- final prediction loss with attention L_f
2.6. Re-weight for Hard Sample
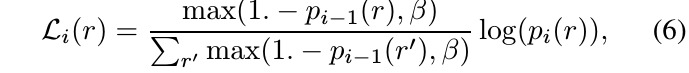
3. Experiments
3.1. Dataset
- ADE ( parts annotations)
- Visual Genome (relationship annotation)
- COCO
3.2. Details
- use provided ground-truth location
- evaluation. classification accuracy (AC) and average precision (**AP); per-class and per-instance**
- word vectors of fastText algorithm
- roll-out the reasoning modules 3 times (more iterations do not offer more help)
3.3. Main Results
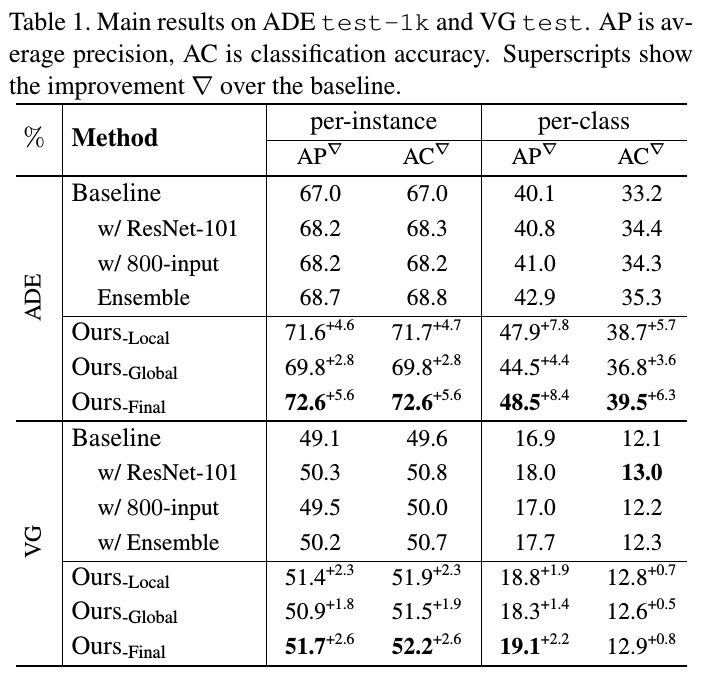
- deeper network and larger image size can only help ~1%, less than ensembles
- proposed models achieve higher per-class metric gains than per-instance ones, indicating that rare classes get helped more
3.4. Ablation
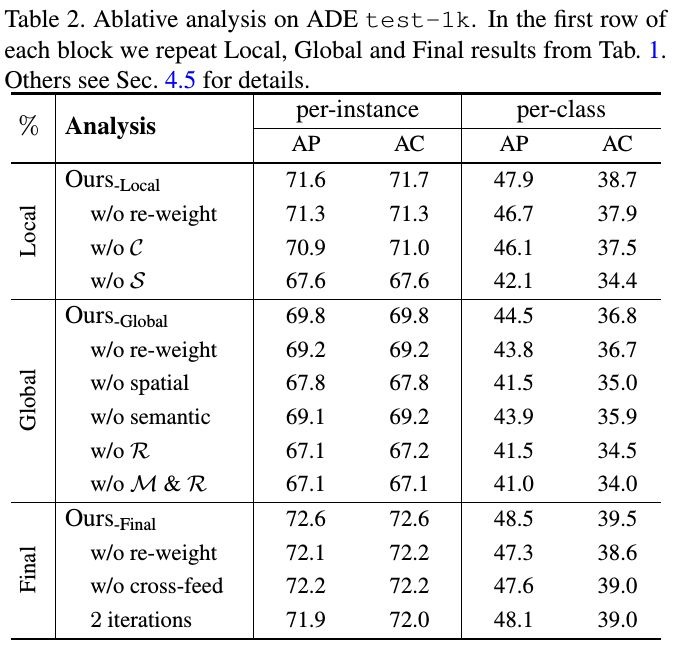
- In the local module, spatial memory S is critical
- In the global module, removing reasoning module R steeply drops performance, whereas further removing memory M dose not hurt much
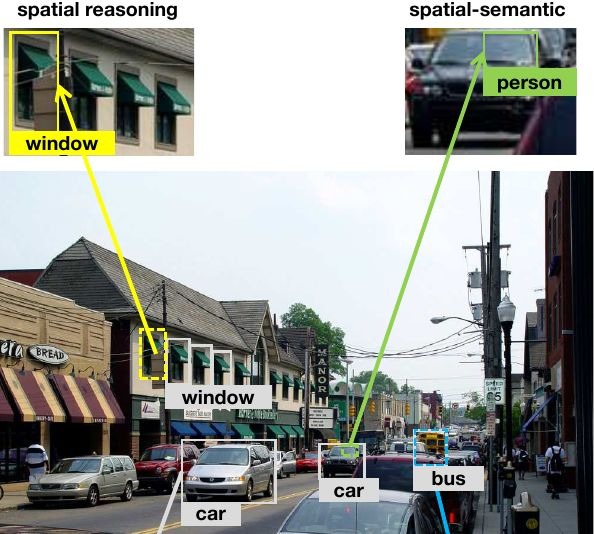
3.5. Visualization
